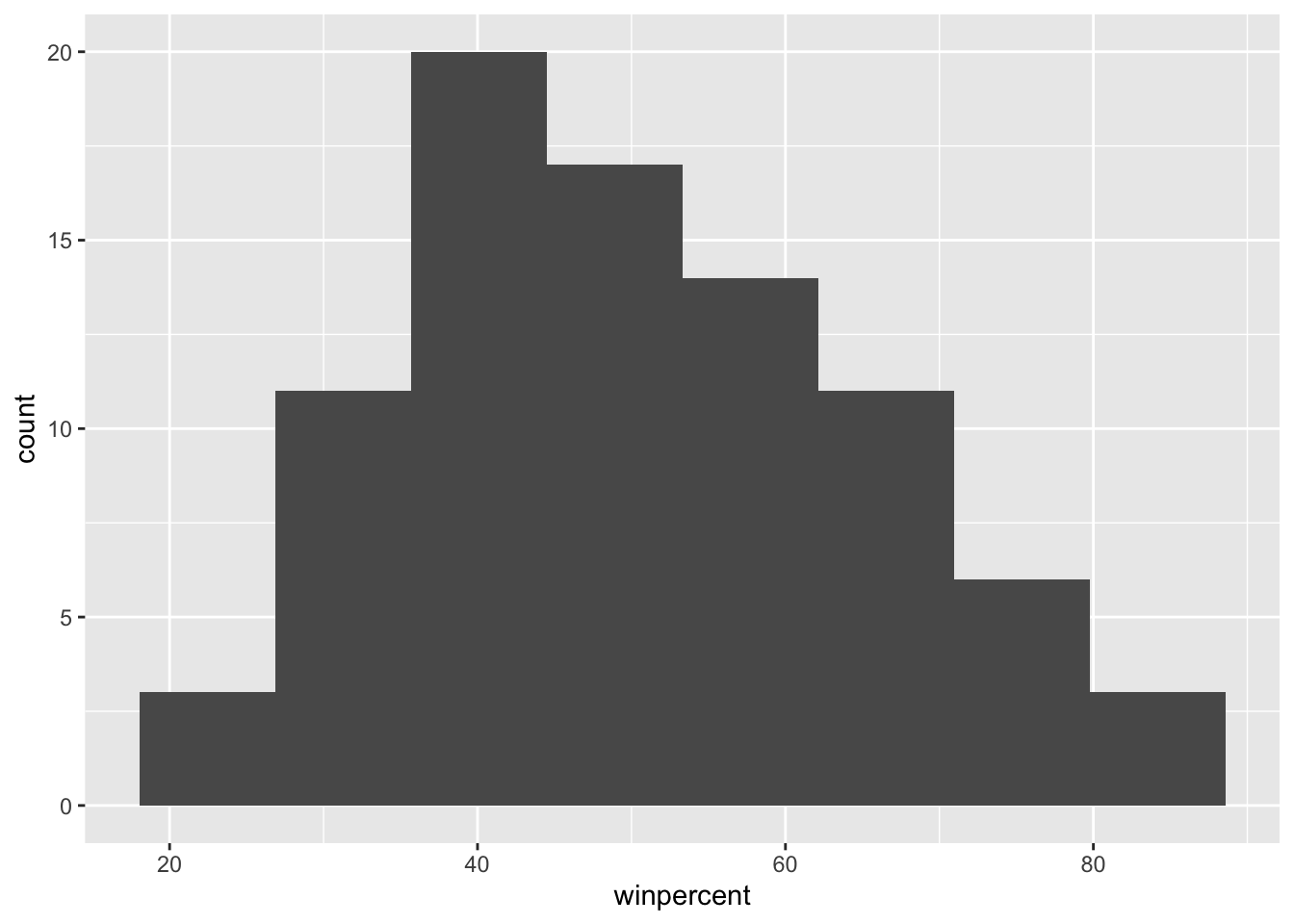
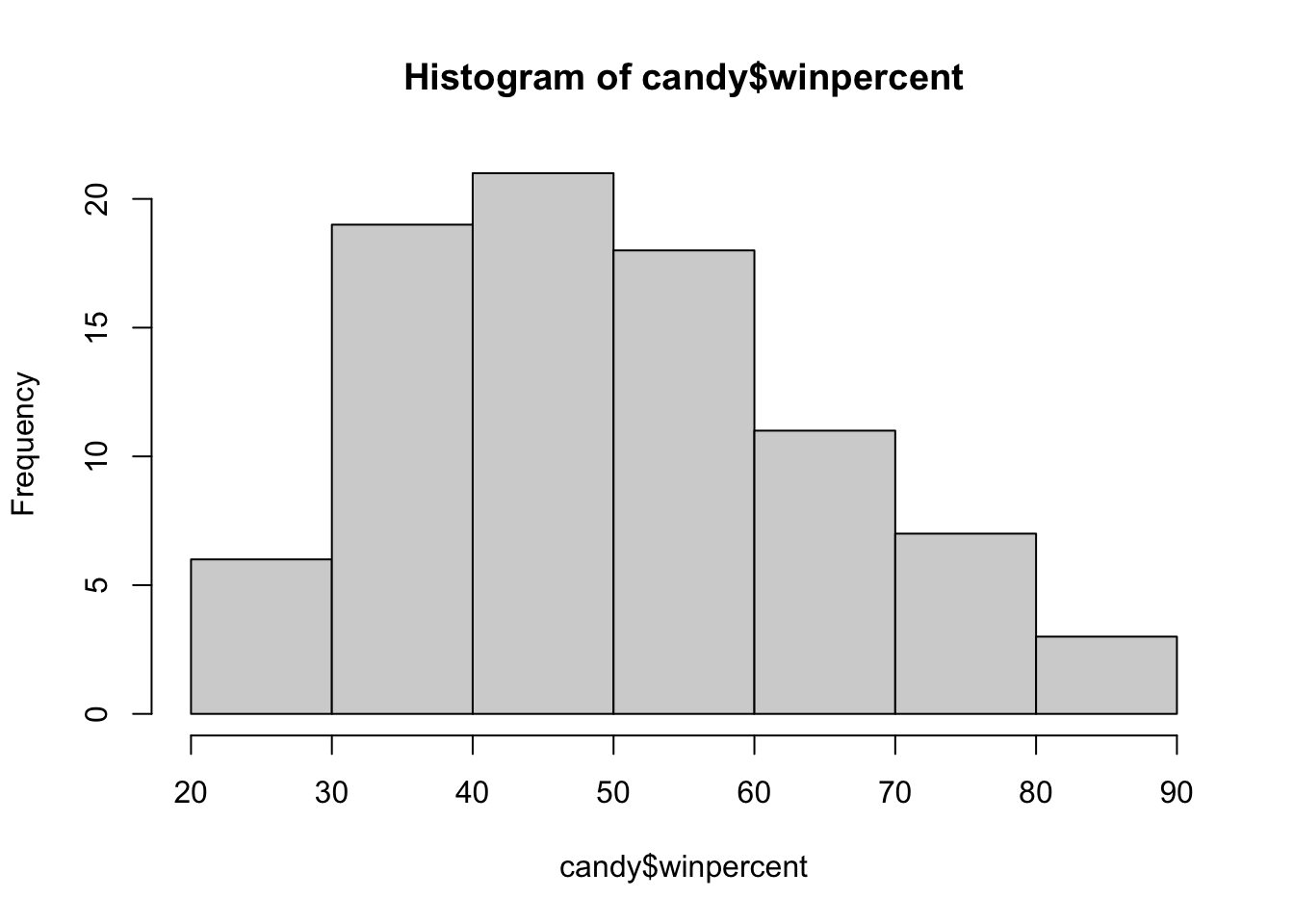
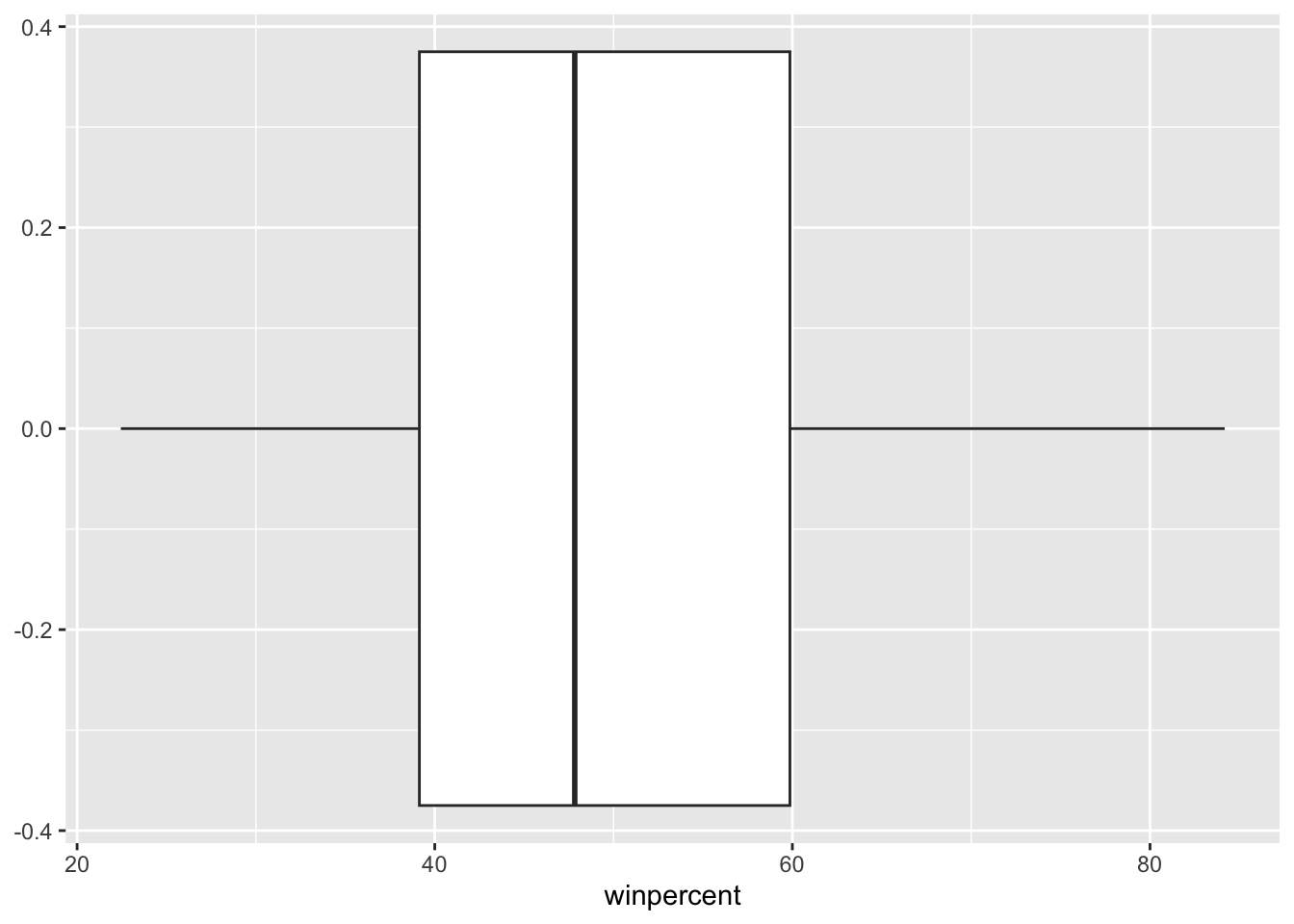
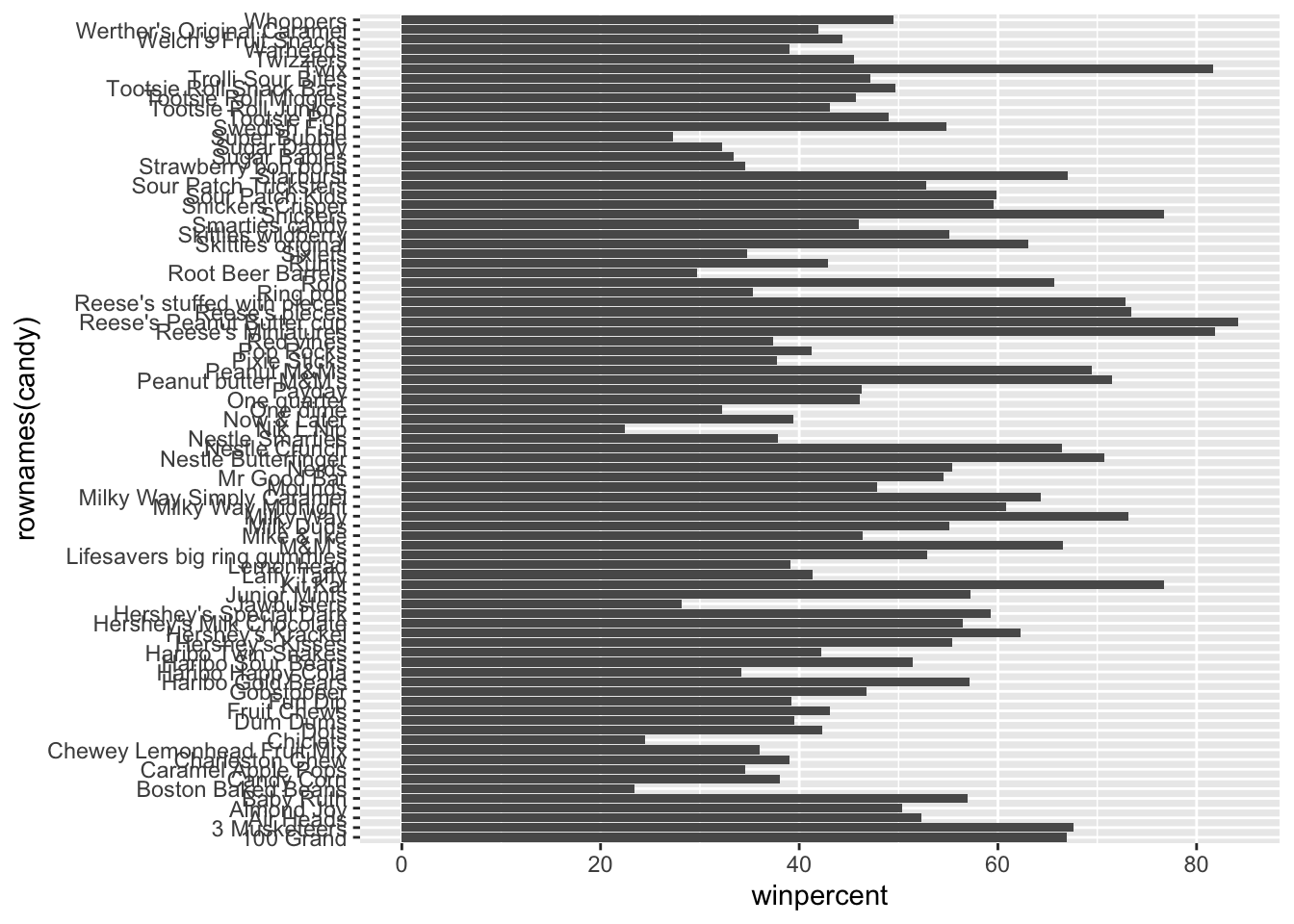
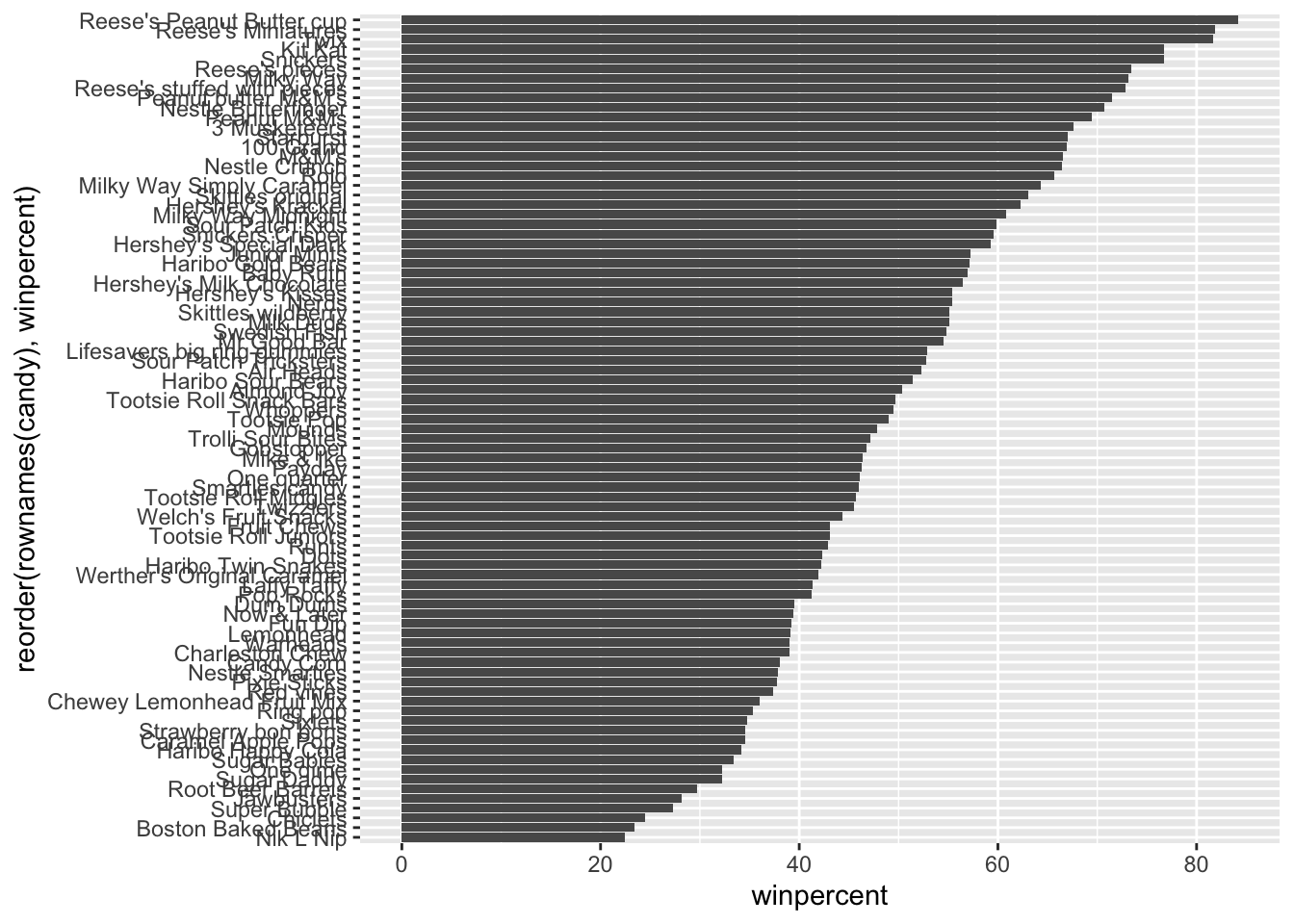
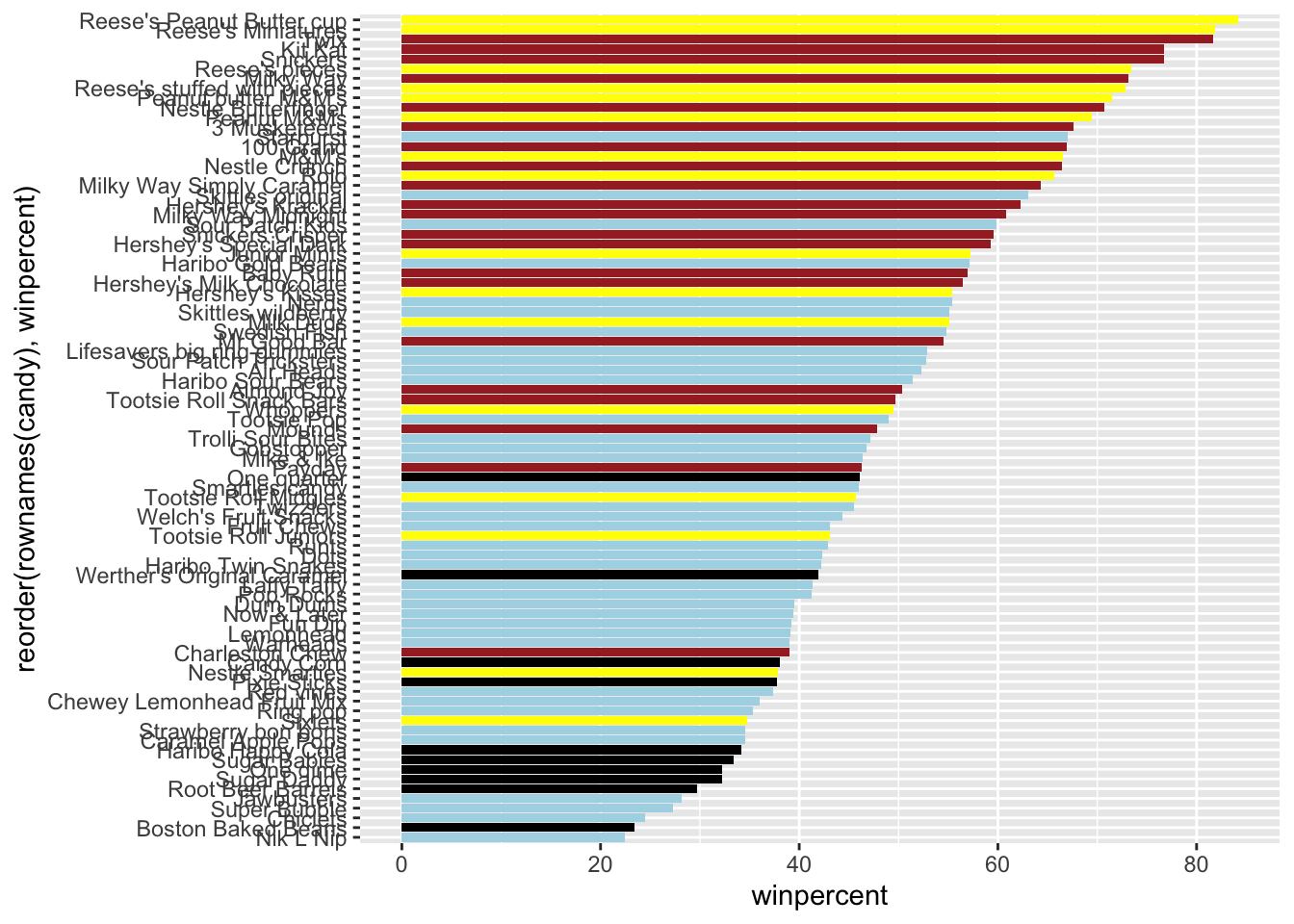
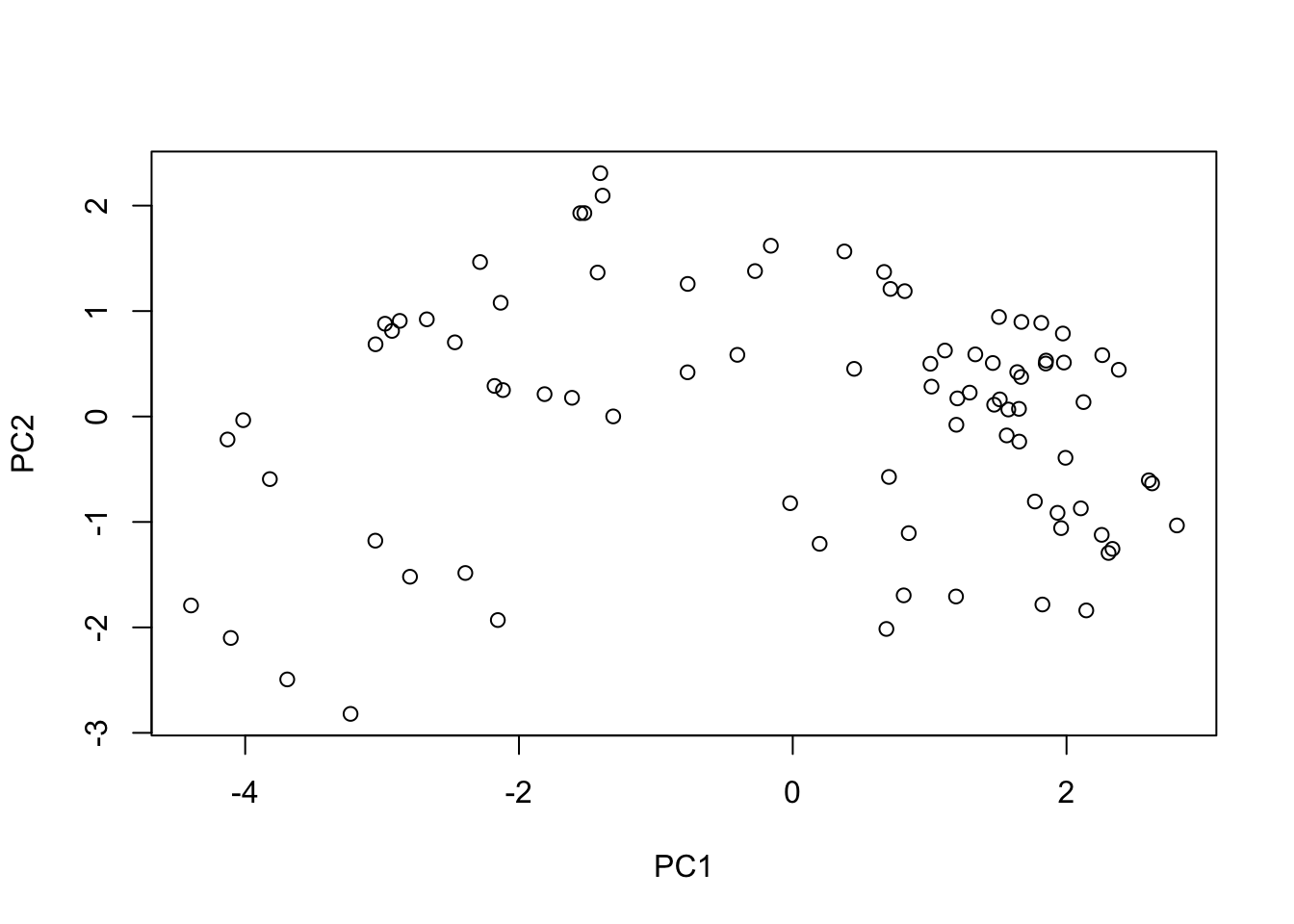
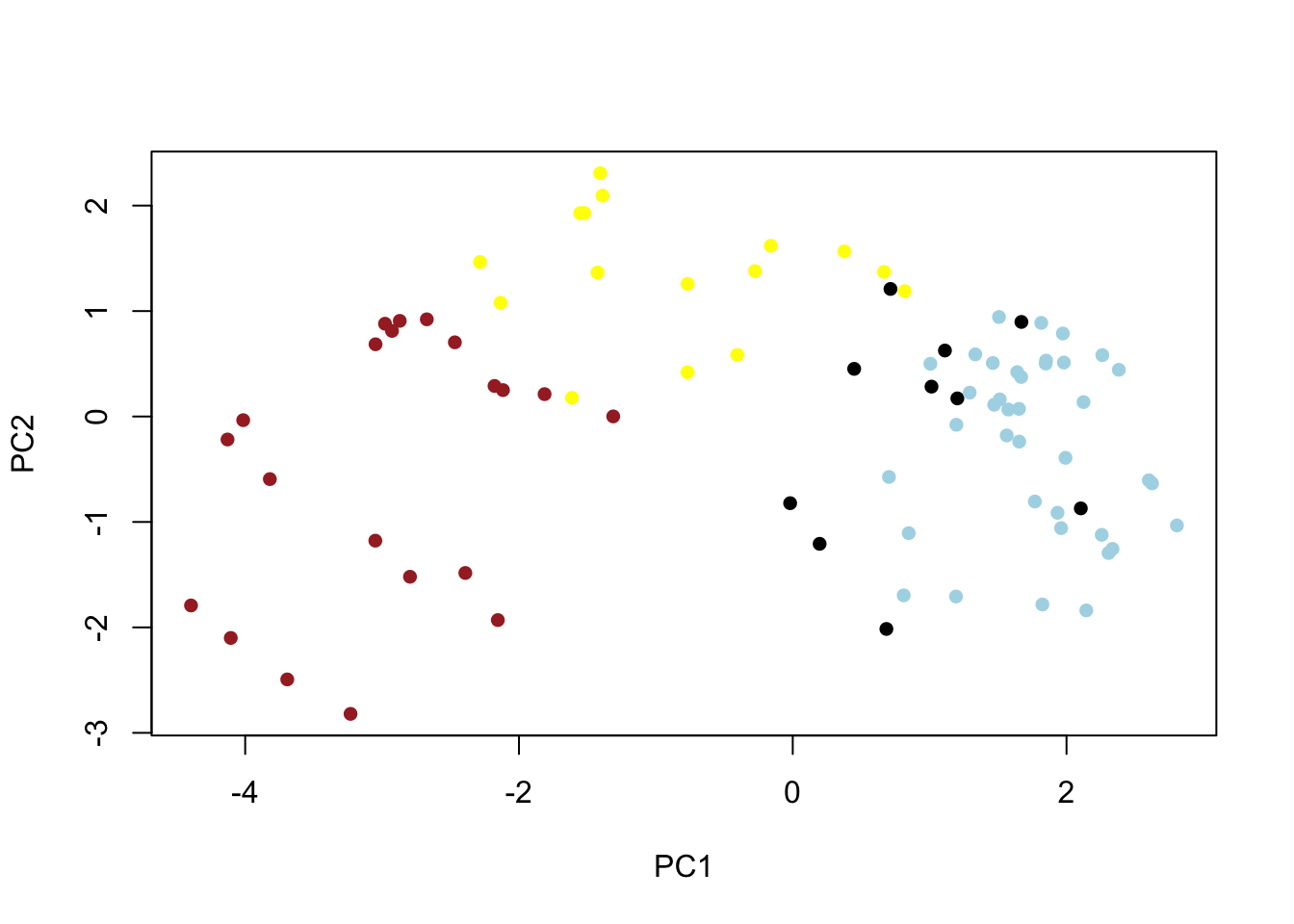
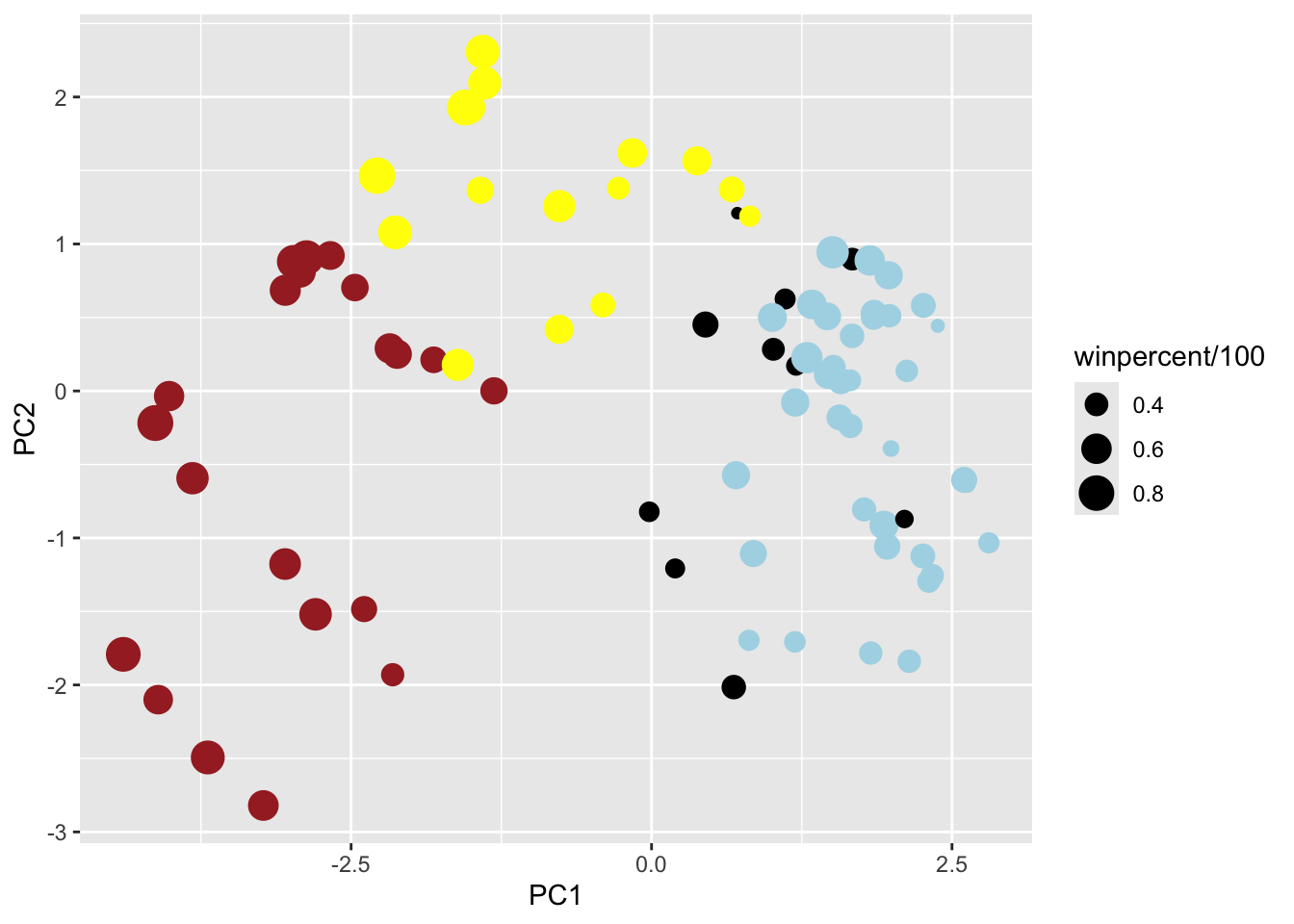
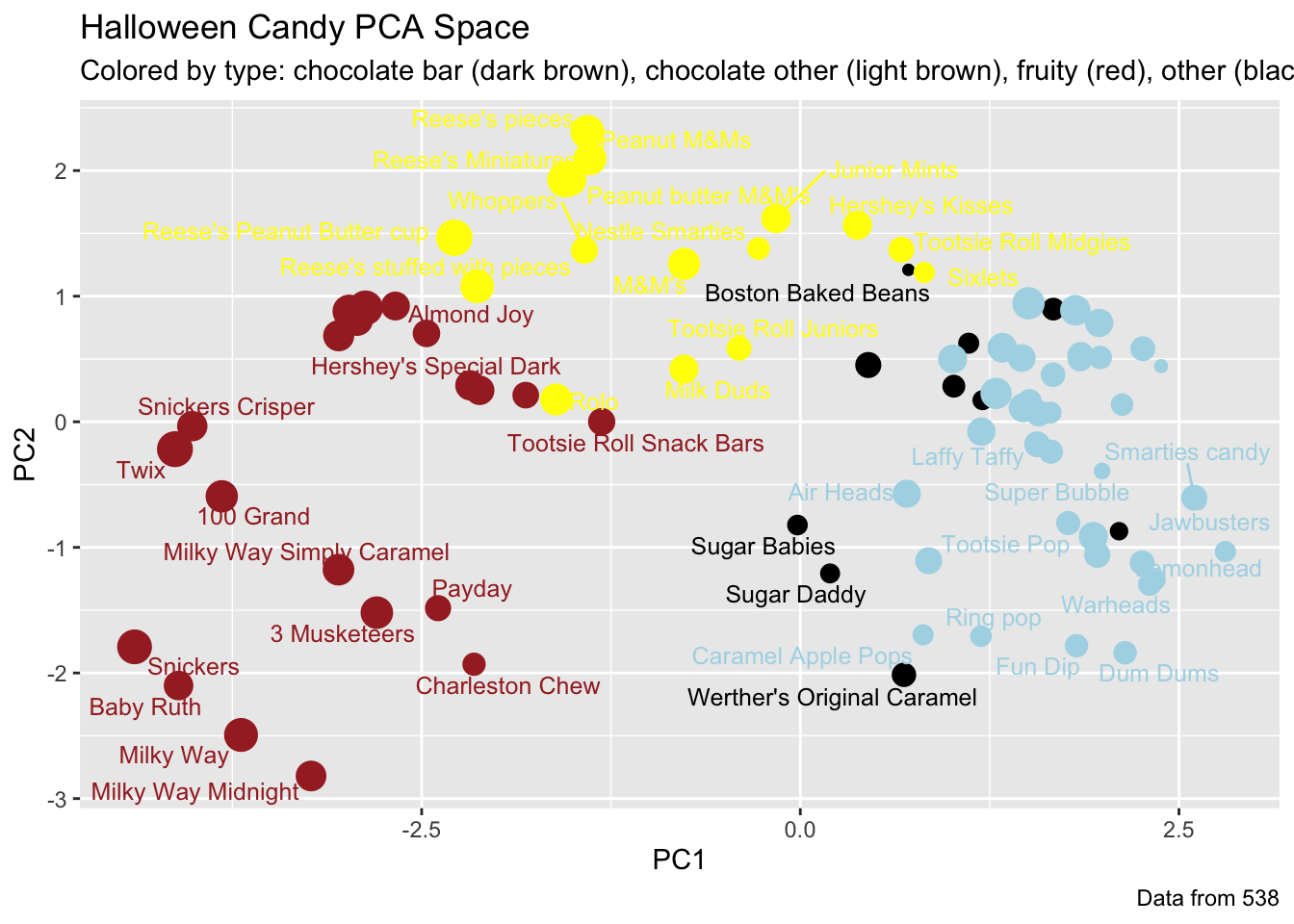
On average, the chocolate candy is higher ranked than fruit candy
Q12. Is this difference statistically significant?
t.test(chocoavg, fruitavg)
Welch Two Sample t-test
data: chocoavg and fruitavg
t = 6.2582, df = 68.882, p-value = 2.871e-08
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
11.44563 22.15795
sample estimates:
mean of x mean of y
60.92153 44.11974
p-value is very small so the difference is statistically significant
Q13. What are the five least liked candy types in this set?
candy |>arrange(winpercent) |>head(5)
chocolate fruity caramel peanutyalmondy nougat
Nik L Nip 0 1 0 0 0
Boston Baked Beans 0 0 0 1 0
Chiclets 0 1 0 0 0
Super Bubble 0 1 0 0 0
Jawbusters 0 1 0 0 0
crispedricewafer hard bar pluribus sugarpercent pricepercent
Nik L Nip 0 0 0 1 0.197 0.976
Boston Baked Beans 0 0 0 1 0.313 0.511
Chiclets 0 0 0 1 0.046 0.325
Super Bubble 0 0 0 0 0.162 0.116
Jawbusters 0 1 0 1 0.093 0.511
winpercent
Nik L Nip 22.44534
Boston Baked Beans 23.41782
Chiclets 24.52499
Super Bubble 27.30386
Jawbusters 28.12744
Q14. What are the top 5 all time favorite candy types out of this set?
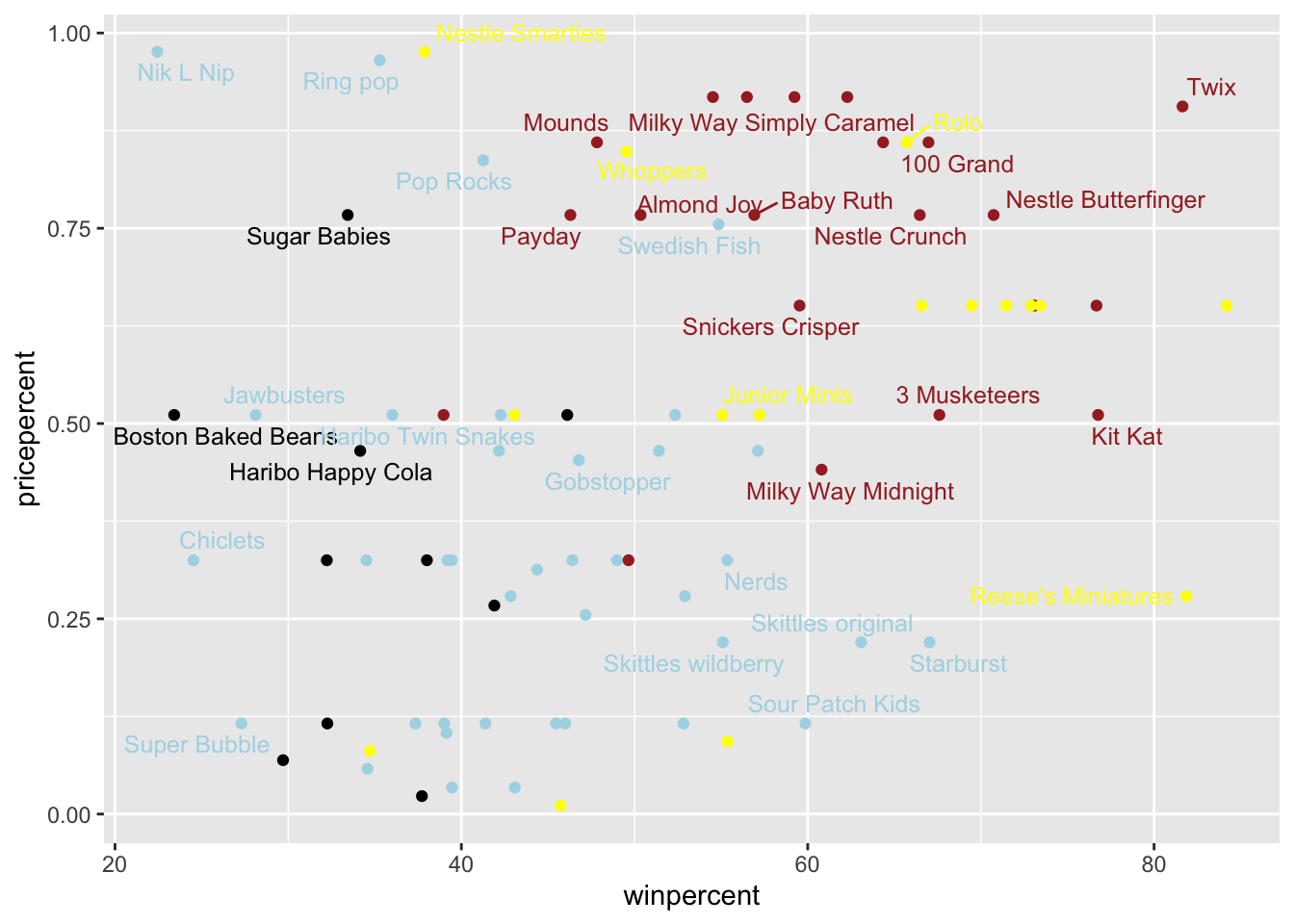
library(ggrepel)# How about a plot of win vs priceggplot(candy) +aes(winpercent, pricepercent, label=rownames(candy)) +geom_point(col=my_cols) +geom_text_repel(col=my_cols, size=3.3, max.overlaps =5)
Warning: ggrepel: 50 unlabeled data points (too many overlaps). Consider
increasing max.overlaps
Q19. Which candy type is the highest ranked in terms of winpercent for the least money - i.e. offers the most bang for your buck?
The candy is Reese’s Miniatures
Q20. What are the top 5 most expensive candy types in the dataset and of these which is the least popular?
ord <-order(candy$pricepercent, decreasing =TRUE)head( candy[ord,c(11,12)], n=5 )
pricepercent winpercent
Nik L Nip 0.976 22.44534
Nestle Smarties 0.976 37.88719
Ring pop 0.965 35.29076
Hershey's Krackel 0.918 62.28448
Hershey's Milk Chocolate 0.918 56.49050
The least popular and the most expensive is Nik L Nip
library(corrplot)
corrplot 0.95 loaded
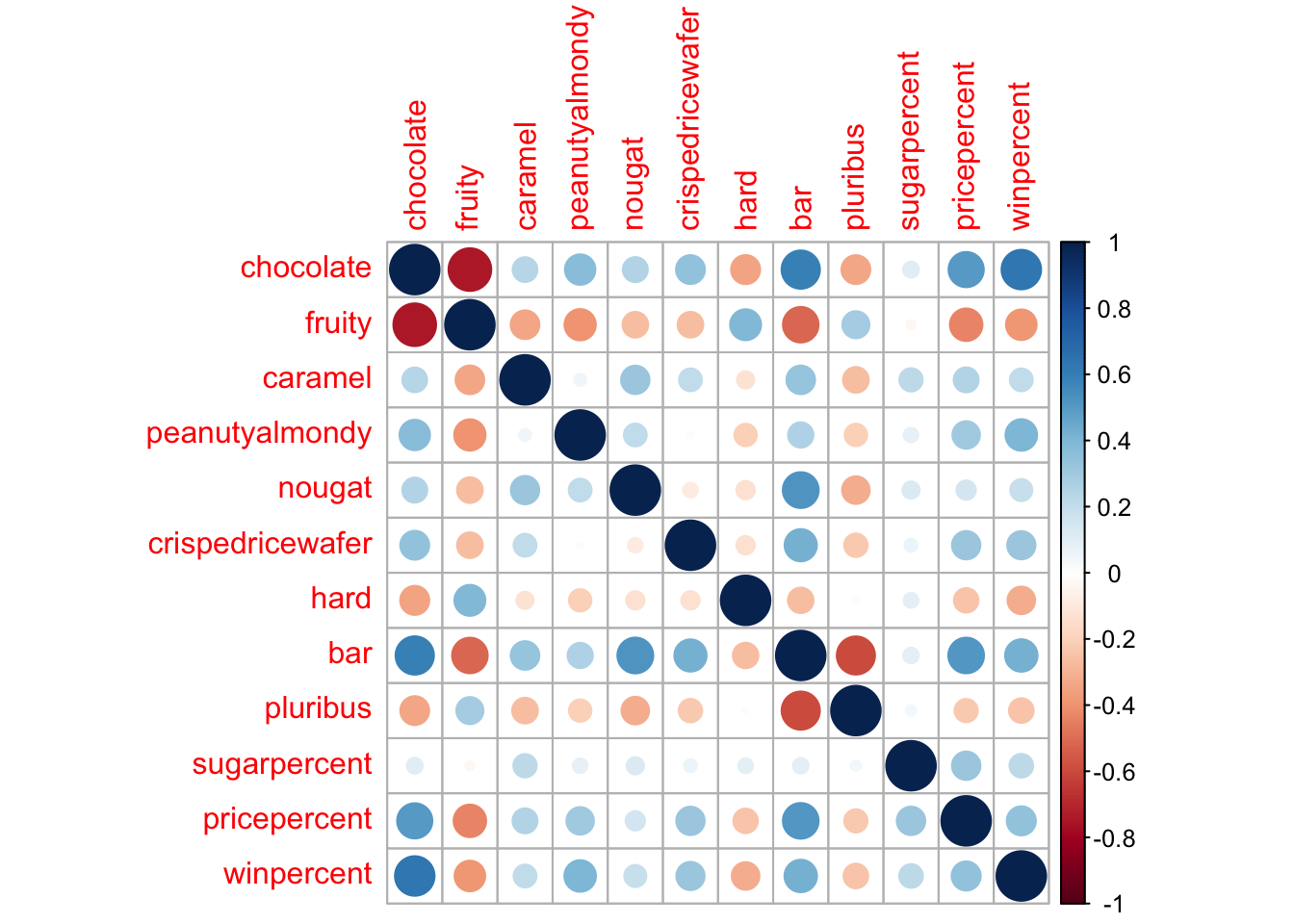
cij <-cor(candy)corrplot(cij)
Q22. Examining this plot what two variables are anti-correlated (i.e. have minus values)?
The chocolate and fruity variables are the most anti-correlated
Q23. Similarly, what two variables are most positively correlated?
The Win percent and chocolate is most positively correlated
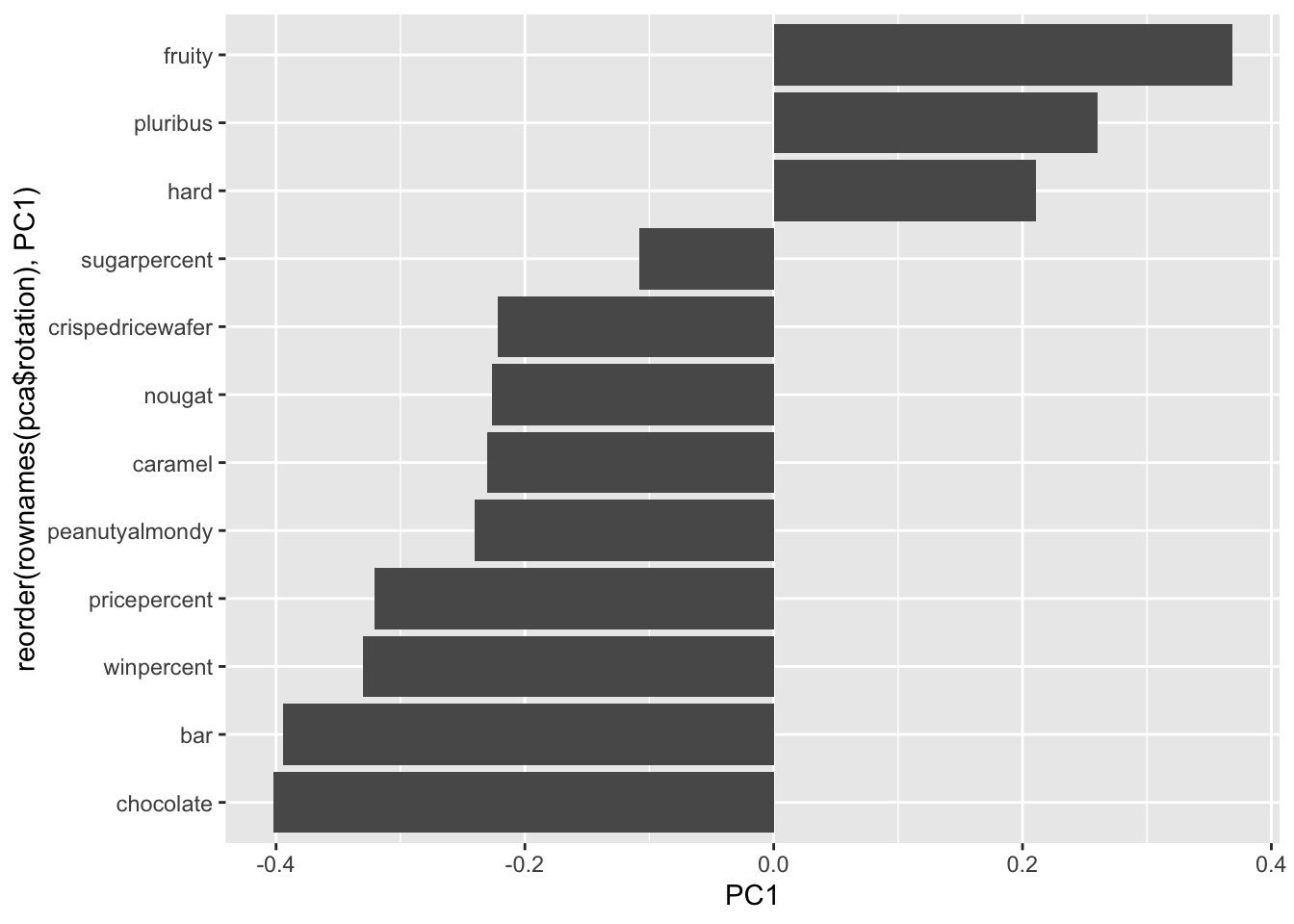
Q24. Complete the code to generate the loadings plot above. What original variables are picked up strongly by PC1 in the positive direction? Do these make sense to you? Where did you see this relationship highlighted previously?
The variables that were picked up strongly by PC1 in the positive value are Fruity, hard, and pluribus. They make sense based on the correlation graph because when comparing them together, they are shown to have positive correlation. This means that PC1 represents candies that are fruity, hard, and pluribus.